
LoadFighters: your reliable assistant in high-load & big data projects
The Admixer team has extensive experience in building high-load systems that process billions of transactions in real time. The application of such systems goes far beyond the advertising industry and can be used by many verticals. We want to share our experience and insights on how companies can build a reliable high-load system for their business and save resources at the same time.
Trends & Problems
The last decade has seen the transfer of infrastructure to clouds and the development of cloud technologies. Clouds are perfect for both startups and a wide range of Enterprise clients. they eliminate the need to build and maintain their infrastructure and DevOps team and have ready-made PaaS & SaaS solutions. They are often able to work according to the Pay As You Go model.
However, cloud technologies are characterized by:
- the high cost of network traffic;
- insufficient optimization on PaaS solutions for specific tasks;
- poor comparability of capacities in the cloud and real physical servers.
Consequently, a considerable cost increase of cloud infrastructure and emergent restrictions is highly noticeable for High Load & Big-Data projects.
Our team has come a long way from using the cloud to its On-Premise platform, which combines the flexibility and low cost of On-Premise with the reliability of the cloud. This allowed us not only to decrease technical costs exponentially but gave rise to the successful construction of High Load & Big Data projects, such as Admixer Advertising Exchange.
Success Cases
Admixer is an AdTech vendor that provides a range of ad management products for brands, advertising agencies, and publishers: an ad-buying platform (DSP), advertising exchange (AdEx), products for media holdings, and site owners.
All of the above products have the exact mechanism – the platform determines who to show which ads to, conducts a price auction and provides a billing mechanism for all participants in the transaction. The cost calculation carries out in real-time based on advertising events (such as showing ads, clicks on ads, etc).
The platform can accept up to 50 billion requests for advertising daily, and for each request, from 1 to 10 advertising events are registered. Each request for advertising serves up to 2 milliseconds. It stores all reported advertising events not just in a simple raw form but aggregates them in near real-time to provide analytics, monitoring by business metrics, and ML models training. The total monthly volume of Internet traffic generated by such requests is 5000 TB, which costs $3000- $5000.
In comparison, the estimated cost of traffic in cloud platforms that charge for outgoing traffic (2500TB):
- Microsoft Azure – $103,399;
- GCP – $118,476;
- AWS – $140,384.
In addition to the cost of traffic, an essential component of High-Load & Big Data projects is the price of units serving business logic and logging events and the cost of a cluster of servers storing and providing data.
For example, it worked with:
- peak load: up to 1,000,000 requests per second;
- dataset size: 200TB of always-available data, in about real-time (3.5PB uncompressed data);
- 3,000,000,000,000 records in databases;
- 40 data slices and and 40 metrics in one table.
Architecture
The architectural solution consists of several components.
- We accept traffic via the HTTP protocol and process it with a cluster of servers running Nginx. In this case, Nginx is a balancer and distributes traffic to further microservices with minimal changes to incoming requests. Since Nginx is optimized for such tasks, a small cluster is needed (approximately 3-5 units).
- The incoming traffic directs to a cluster of microservices written for specific cases in the Golang language, that allows receiving traffic with minimal cost, to carry out the necessary processing (including obtaining data from the outside), to make requests to Key-Value Storages (Redis, Aerospike) and to record this data to the storage cluster. The object model applies within the microservices cluster, which fetches asynchronously from relational DBMSs. Also, in some microservices, the ML model is called in real-time. The number of servers and capacities required for a network of microservices depends on the specific tasks that this stack must perform
- The next element in the diagram is a cluster of Clickhouse servers used to store and quickly receive data. Clickhouse is a freeware that eliminates the licensing and cost factor. Clickhouse allows to process large amounts of data in time close to real-time, can quickly scale and replicate data, has good optimization and mechanisms for aggregating and compressing stored data. Availability of built-in functions allows transferring many tasks and calculations from the client to the server-side.
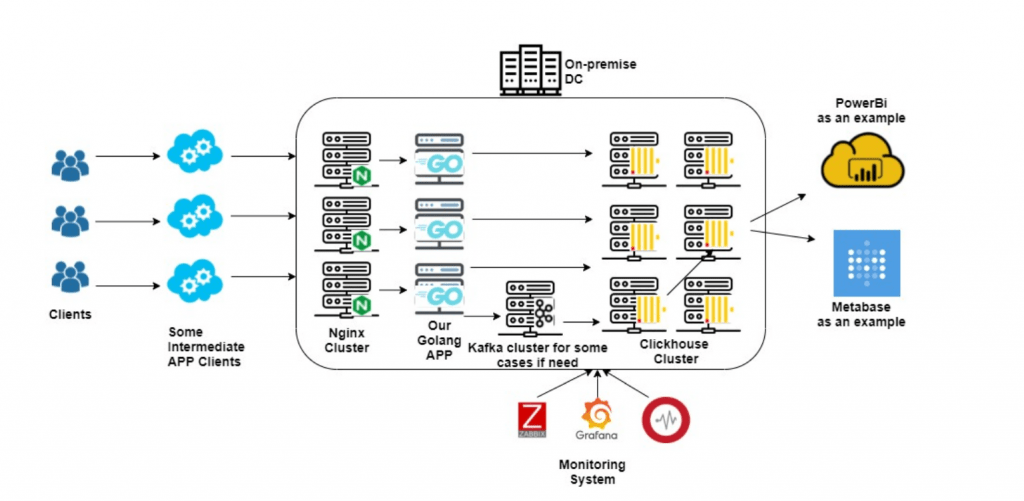
Infrastructure
We use On-Premise data centers with a Tier-3 or higher level, in which we rent dedicated servers of various configurations with a monthly payment. Moving to dedicated servers and separate data centers allows to maximize the use of server capacity while reducing the overall cost.
Dedicated servers allow reducing traffic costs by 10-40 times compared to the cloud. More accurate optimization for specific tasks is possible, including close network interaction with the data center. Also, the presence of dedicated servers allows not to focus on problems related to physical equipment directly, setting up and maintaining the network.
Our experience of working with different providers, including cloud ones, led us to a
dedicated server system with the following advantages:
- availability of connections and agreements with proven data centers in different geolocations;
- low cost of traffic – $ 1-5 per TB, depending on geolocation and the amount of required traffic;
- availability of servers of different configurations for a more accurate selection of equipment.
Monitoring
The monitoring system ensures continuity and efficiency of work, and we have two types
of monitoring:
1) monitoring the system’s performance: monitoring, responding to emerging problems both in the field of physical equipment and the correct functioning of the software;
2) monitoring of key business indicators, the changes of which could be caused, for example, by an error in business logic.
Since it is crucial to catch and report the issue to the responsible person in time, we integrate monitoring systems with various instant messengers, including SMS and calls. As a basis, we use:
- open-source applications for collecting monitoring metrics – Zabbix, Grafana, collecting logs for various products, such as Graylog or ELK stack, and configuration and integration with paid products – DataDog, NewRelic, etc.;
- self-written programs for specific cases;
- integration with products aimed at making phone calls and sending messages to different messengers: Slack, Telegram, etc.
Security
The system described above can easily be placed both in a separate leased data center at the request and in the client’s infrastructure. All software up to the OS is installed up to the latest versions with all security patches applied. It is possible to upgrade and patch the system without interrupting its operation with ease. If the system is deployed at the client’s facilities, there is no need for network interaction with the outside world.
Based on the client’s requirements, we can:
- build a system for working with data according to the specified requirements and security patterns;
- describe and configure the security system according to generally accepted approaches in the absence of a centralized approach in the company.
Data Analysis
Collecting and storing data is not the end goal of working with data. We use several simultaneous approaches to data analysis:
1) automatic analysis – the use of ML models to identify non-obvious dependencies, correlations, and possible automatic adjustment to incoming data. This allows you to respond quickly to changes (even without human intervention), find Key Indicators on which you need to focus, and predict and build effective scenarios for working with Key Indicators. We mainly use writing models in Python, using the popular libraries Catboost, PyTorch, TensorFlow.
2) manual analysis – preparing data for decision-makers in a clear, understandable, and visually oriented form. Data output in tabular form with a wide range of views and metrics (OLAP) allows to analyze data from different angles, understand trends and possible behaviors of key business metrics. We integrate data warehouses with business intelligence products such as Power BI or Metabase (open source).
Usage Scenarios
A similar stack is applicable not only for AdTech but for any high load & big data projects with an event-based approach in various industries:
- real-time booking;
- online MMO RPG;
- retail and e-commerce;
- telecom;
- fintech.
Need to develop a high-load system?
DevOps, high-load, and big data architecture consulting, design & development with possible subsequent support.
Want to know more about our services?
Visit Loadfighters page or fill in the form to talk to our experts



